

ALEXANDRIA Internet Archive Search Prototype
 ArchiveSearch provides, for the first time, entity based search and exploration functionalities into the Web Archive of the Internet Archive allowing you to use (most of) the 1.9 million concepts of the German Wikipedia or (most of) the 5 million concepts of the English Wikipedia as search terms.
ArchiveSearch provides, for the first time, entity based search and exploration functionalities into the Web Archive of the Internet Archive allowing you to use (most of) the 1.9 million concepts of the German Wikipedia or (most of) the 5 million concepts of the English Wikipedia as search terms.
For these search terms, the current version provides the most important results from the Internet Archive, ranking resources based on Bing search, with more sophisticated re-ranking in future releases, as well as related entity suggestions for most of the queries.
ArchEE – Archive Exploration Engine
 When exploring news archives, a key requirement of historians is to get an overview of their search results initially. To address this problem we developed a novel retrieval model – HistDiv – which ranks articles according to historical relevance. The Archive Exploration Engine (ArchEE) system was built to showcase how HistDiv and various other state-of-the-art retrieval models coupled with time-lines and entity filters can help users better explore large news archives.
When exploring news archives, a key requirement of historians is to get an overview of their search results initially. To address this problem we developed a novel retrieval model – HistDiv – which ranks articles according to historical relevance. The Archive Exploration Engine (ArchEE) system was built to showcase how HistDiv and various other state-of-the-art retrieval models coupled with time-lines and entity filters can help users better explore large news archives.
ArchEE also been selected as one of the top 3 startups in Lower Saxony for the 2016 Going Global competition organized by Hannover Impuls.
Tempas – Temporal Archive Search Based on Tags
 Limited search and access patterns over Web archives have been well documented. One of the key reasons is the lack of understanding of the user access patterns over such collections, which in turn is attributed to the lack of effective search interfaces. Current search interfaces for Web archives are (a) either purely navigational or (b) have sub-optimal search experience due to ineffective retrieval models or query modeling. We identify that external longitudinal resources, such as social bookmarking data, are crucial sources to identify important and popular websites in the past. To this extent we present Tempas, a tag-based temporal search engine for Web archives.
Limited search and access patterns over Web archives have been well documented. One of the key reasons is the lack of understanding of the user access patterns over such collections, which in turn is attributed to the lack of effective search interfaces. Current search interfaces for Web archives are (a) either purely navigational or (b) have sub-optimal search experience due to ineffective retrieval models or query modeling. We identify that external longitudinal resources, such as social bookmarking data, are crucial sources to identify important and popular websites in the past. To this extent we present Tempas, a tag-based temporal search engine for Web archives.
Websites are posted at specific times of interest on several external platforms, such as bookmarking sites like Delicious. Attached tags not only act as relevant descriptors useful for retrieval, but also encode the time of relevance. With Tem- pas we tackle the challenge of temporally searching a Web archive by indexing tags and time. We allow temporal selections for search terms, rank documents based on their popularity and also provide meaningful query recommendations by exploiting tag-tag and tag-document co-occurrence statistics in arbitrary time windows. Finally, Tempas operates as a fairly non-invasive indexing framework. By not dealing with contents from the actual Web archive it constitutes an attractive and low-overhead approach for quick access into Web archives.
Tempurion – A Collaborative Temporal URI Collection for Named Entities
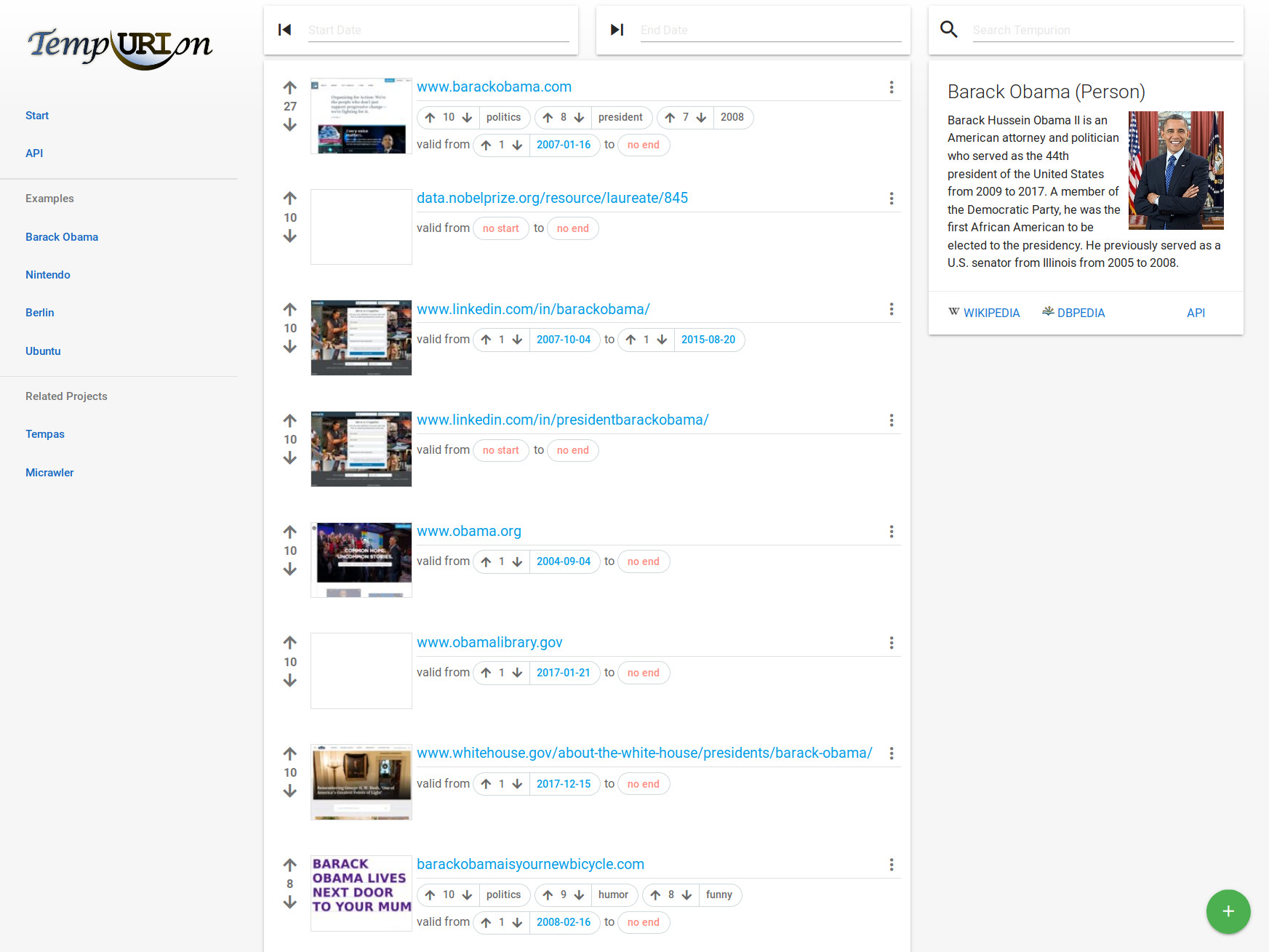 Web archives represent crucial endeavors in preserving the web from the past and provide a valuable resource for researchers of different disciplines. Due to their size, navigation in these collections is often limited to specifying an URI and the desired date. However, typical research questions often revolve around the evolution of entities instead of specific websites. Although full-text search often seems to be the first choice to look up Web pages, while it provides a quick way to yield the best match with a keyword, its diversified ranking is not made for compiling reliable entity related collections. Further, it generally ignores the temporal relevance that is needed to find pages from the past, e.g., in Web archives.
Web archives represent crucial endeavors in preserving the web from the past and provide a valuable resource for researchers of different disciplines. Due to their size, navigation in these collections is often limited to specifying an URI and the desired date. However, typical research questions often revolve around the evolution of entities instead of specific websites. Although full-text search often seems to be the first choice to look up Web pages, while it provides a quick way to yield the best match with a keyword, its diversified ranking is not made for compiling reliable entity related collections. Further, it generally ignores the temporal relevance that is needed to find pages from the past, e.g., in Web archives.
Tempurion provides ordered lists of resources, characterizing named entities over time. For this purpose, different datasets were collected and evaluated by comparing each with a combination of others. Based on these quality assessments, we eventually created an initial database to power our system. Benchmarked against Web search engines, our approach achieves a remarkable precision of 83.3 % and shows promising results for high-quality lookups and temporal collection building. To not only rely on existing datasets, we have implemented interactive mechanisms to get humans in the loop to expand the collection by contributing URIs, metadata and temporal information as well as to correct errors.
https://tempurion.l3s.uni-hannover.de
EventKG+TL – Cross-lingual Event Timelines
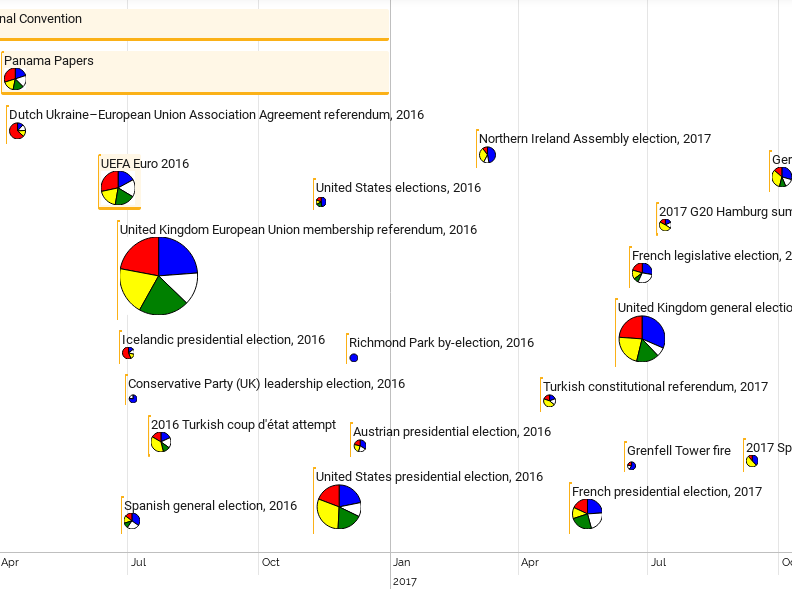 Multilingual event-centric temporal knowledge graphs enables structured access to representations of a large number of historical and contemporary events in a variety of language contexts. Timelines provide an intuitive way to facilitate an overview of events related to a query entity over a certain period of time.
Multilingual event-centric temporal knowledge graphs enables structured access to representations of a large number of historical and contemporary events in a variety of language contexts. Timelines provide an intuitive way to facilitate an overview of events related to a query entity over a certain period of time.
EventKG+TL generates cross-lingual event timelines and facilitates an overview of the language-specific event relevance and popularity along with the cross-lingual differences.
http://eventkg-timeline.l3s.uni-hannover.de/
MultiWiki – Text Passage Extraction and Alignment for Interlingual Article Pairs in Wikipedia
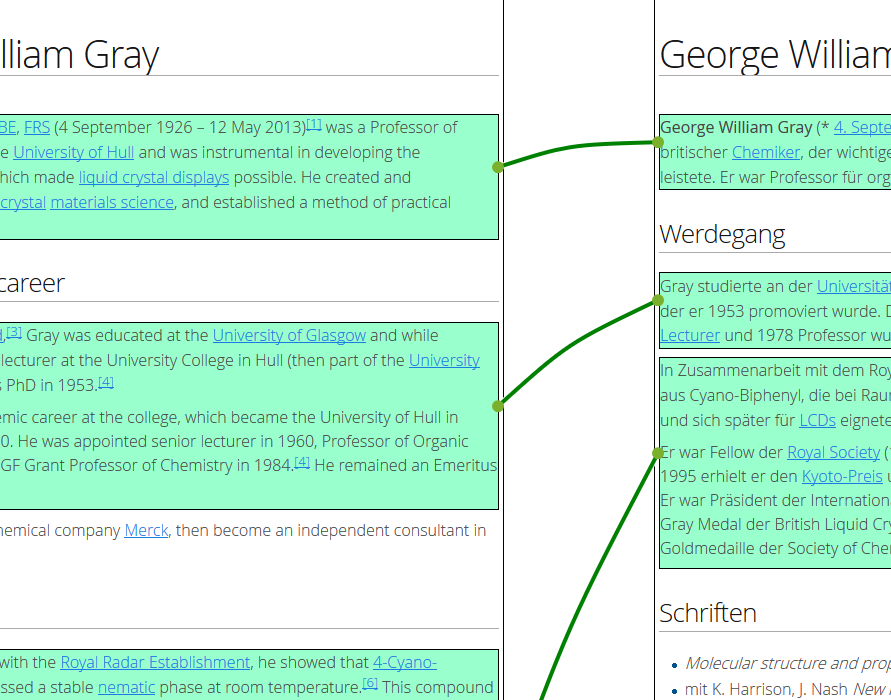 Wikipedia articles in different language editions evolve independently within the scope of the language-specific user communities. This can lead to different points of views reflected in the articles.
Wikipedia articles in different language editions evolve independently within the scope of the language-specific user communities. This can lead to different points of views reflected in the articles.
MultiWiki provides an overview of the similarities and differences across the article pairs originating from different language editions on a timeline. It enables users to observe the changes in the interlingual article similarity over time and to perform a detailed visual comparison of the article snapshots at a particular time point.