

We distinguish three main Wikipedia dataset derivatives. All three cases operate on the revision history of Wikipedia. This release consists of Wikipedia revisions until 16/11/2016.
Due to the large size of the Wikipedia datasets, we provide only small sample, however, we on request to the ALEXANDRIA team, we can provide the complete dataset repository.
Wikipedia Article–Section Analysis
Articles in Wikipedia are structured into sections. The structure of sections is nested, and for each section there can be sub-sections up to a certain depth.

For example, the image on the left shows the section structure for the article about Angela Merkel.Accessing and analyzing the longitudinal information provided in different sections, reveals several interesting aspects of the article. For example, in this case, for Angela Merkel, before being elected as a chancellor of Germany, the corresponding section “Chancellor of Germany” would be missing. This in many cases can represent an indicator of important events for the article under consideration. A similar example is the section “Honorary and awards” .
We provide the mechanism for extracting such information and provide the temporal dataset, which corresponds to Wikipedia articles and their respective section structure at any time point in their revision history.
Below we show a code snippet (in JAVA) on how one can extract such information from a Wikipedia article at any given timepoint. The code is part of the libraries developed and made publicly available as part of the ALEXANDRIA outcomes.
WikipediaEntity entity = new WikipediaEntity();
entity.setTitle("Angela Merkel");
//specify if we are interested only in main sections or all the sub-sections.
entity.setMainSectionsOnly(true);
//the content of the article from the revision history
entity.setContent(entity_text);
//iterate over all the head sections in this article
Set sections = entity.getSectionKeys(2);
for(String section:sections){
WikiSection section = entity.getSection(section);
}
Through this simple snippet we are able to generate a temporal dataset consisting of all articles and their corresponding sections from the entire revision history of Wikipedia. An example snippet of the dataset is shown below.
{
"revision_id":0l,
"entity":"Angela Merkel",
"sections":[
{
"section":"Early life",
"level":2,
"text":"Merkel was born Angela Dorothea Kasner [...] "
}
]
}
Use Cases
In context of ALEXANDRIA, we made use of the above dataset for enriching and suggesting news citations to Wikipedia articles, correspondingly to the appropriate sections.
For instance, if we are about to suggest a news article, we first check if the entity or Wikipedia article is important in the news article, then later determine for which section it is more appropriate. 
When using this subset of data, please cite the publication below.
Download
We extracted the citations and split the articles into the corresponding sections for the entire Wikipedia revision history. The dataset is available for download and below we show some of the statistics of the dataset.
Wikipedia Citation Extractor
An important part of Wikipedia are its citations to external references. These have great value because they serve as evidence for the added statements. To simplify analysis and answer questions with respect to how citations are added, the type of sources that are referred most, and other questions, we have developed extractors and correspondingly have made the extracted citations from the entire revision history available for download.
To extract citations and the context in which they are cited or the so called citing statements, we use the developed mechanisms as part of ALEXANDRIA which are available for download, and we show an example code snippet below.
WikipediaEntity entity = new WikipediaEntity();
entity.setTitle("Angela Merkel");
//specify if we are interested only in main sections or all the sub-sections.
entity.setMainSectionsOnly(true);
//set first the flag for extracting citations to true
entity.setExtractCitations(true);
//set the content of an article and now here we extract citations too
entity.setContent(entity_text);
//get all the extracted citations which are uniquely identified within the article
Map<Integer, Map<String, String>> citations = entity.getEntityCitations();
//for all the citations extract their citation context or citing statements
Map<Integer, Map<String, List>> citing_statements = entity.getCitingStatements();
//iterate over the extracted citations
for(int citation_id:citations.keySet()){
Map<String, String> citation_attributes = citations.get(citation_id);
//there are several citation attributes we can access
//e.g. citation type, url etc.
String cite_type = citation_attributes.get("cite_type");
String url = citation_attributes.get("url");
//for the citing statements we extract also the section
//a citation can occur multiple times in an article
for(String section:citing_statments.get(citation_id).keySet()){
List statements = citing_statements.get(citation_id).get(section);
}
}
There are various ways of processing the citations and their corresponding citing statements through the tools provided in this project. We provide the dataset of all citations and the citing statements extracted in the format shown below.
{
"entity":"Angela Merkel",
"citations":[
{
"cite_id":0,
"url":"http://example.org",
"section":"Early life",
"section_level":2,
"statement":"The family moved to Templin and Merkel grew up in [...]"
}
]
}
The dataset for the entire Wikipedia revision history is available for download as part of the Temporal Wikipedia testbed.
Use Cases
While there are a wide variety of questions and interesting points to investigate citations and their context in Wikipedia. In Alexandria, we focused mainly in two use-cases:
- News Citation Recommendation
- Citation Span
In the first problem we focused on how we can suggest automatically news citations for statements in Wikipedia. We decided in order to suggest an appropriate citation, we first needed to determine which type of citation is most appropriate. For example, in Wikipedia, there are citation to sources like books, web, news, journal, notes, blogs etc. After that, for those that news was most appropriate we found such references from a large news collection. The overview is shown below and the details of the methodology are published here.
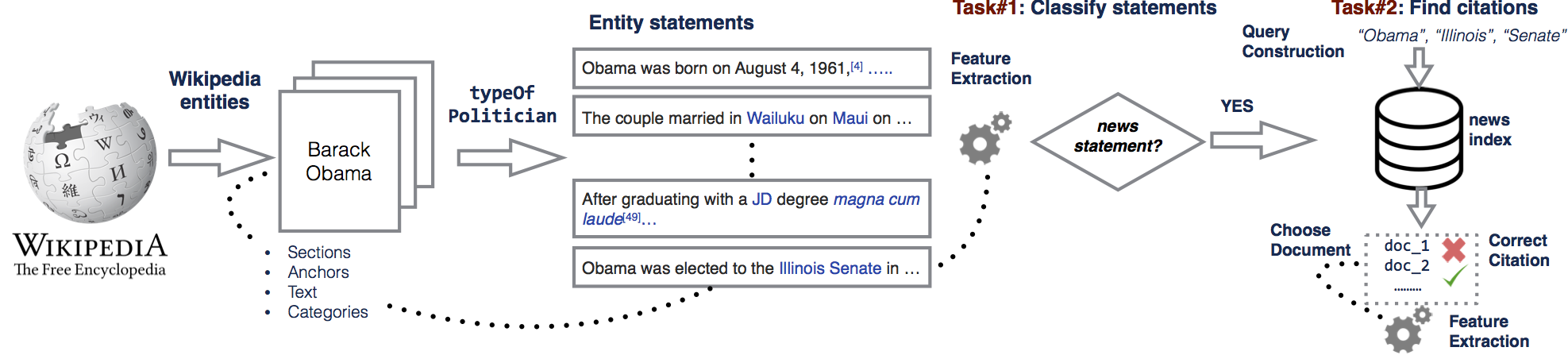
Apart from the raw analysis which can be carried on citations extracted from the Wikipedia articles and their corresponding sections, the dataset can be used similarly as in the use case of News Citation Recommendation as a ground-truth dataset, for example, for training models which are able to suggest automatically news or other types of citations to Wikipedia articles. When using this dataset, please cite the publication shown below.
In the second problem, we tried to solve the problem of determining the actual span of existing citations in Wikipedia. This is an important question given that there are no explicit indicators in Wikipedia of such span, and this would facilitate the process of finding out what part of Wikipedia is actually covered by citations. An example result of our proposed approach shows the marked fragments in a Wikipedia paragraph that are covered by a citation.

Here, we provide a small ground-truth dataset which consists of 500 paragraphs and citation pairs, for which we provide the citation span at the sub-sentence level. The dataset is available for download, and when using please make sure you cite the publication below.