

Datasets
German and UK web archive
Web archives have been instrumental in digital preservation of the Web and provide great opportunity for the study of the societal past and evolution. These Web archives are massive collections of Snapshots of web resources, taken at given point in time. They allow researches to analyse past versions of particular websites or the web at …
Temporal Wikipedia
We distinguish three main Wikipedia dataset derivatives. All three cases operate on the revision history of Wikipedia. This release consists of Wikipedia revisions until 16/11/2016. Due to the large size of the Wikipedia datasets, we provide only small sample, however, we on request to the ALEXANDRIA team, we can provide the complete dataset repository. …
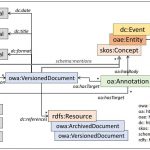
Semantic Layers
What is a Semantic Layer? A Semantic Layer is an RDF repository (RDF graph) of structured data about a collection of archived documents. Structured data includes not only metadata information about a document (like publication date), but also entity annotations, i.e., disambiguated entities mentioned in each document extracted using an entity linking system. The following figure …
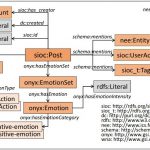
TweetsKB
TweetsKB is an RDF corpus of anonymized data for a large collection of annotated tweets. The dataset currently contains data for more than 1.5 billion tweets, spanning more than 5 years (February 2013 – March 2018). Metadata information about the tweets as well as extracted entities, sentiments, hashtags and user mentions are exposed in RDF using …
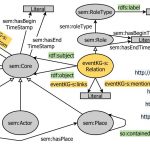
EventKG
EventKG is a novel multilingual resource incorporating event-centric information extracted from several large-scale knowledge graphs such as Wikidata, DBpedia and YAGO, as well as less structured sources such as the Wikipedia Current Events Portal and Wikipedia event lists in five languages. The EventKG is an extensible event-centric resource modeled in RDF. It relies on Open …