

TweetsKB is an RDF corpus of anonymized data for a large collection of annotated tweets. The dataset currently contains data for more than 1.5 billion tweets, spanning more than 5 years (February 2013 – March 2018). Metadata information about the tweets as well as extracted entities, sentiments, hashtags and user mentions are exposed in RDF using established RDF/S vocabularies. For the sake of privacy, we encrypt the tweet IDs and usernames and we do not provide the text of the tweets.
The dataset can relieve data consumers from the computationally intensive process of extracting and processing tweets, while it also facilitates a variety of multi-aspect data consumption, exploration and analytics scenarios including
- time-aware and entity-centric exploration of the Twitter archive
- data integration by directly exploiting existing knowledge bases (like DBpedia)
- entity-centric analytics and knowledge discovery by inferring multi-aspect information related to one or more entities during certain time periods (like popularity, attitude or relations with other entities)
More information, as well as examples and use cases, are available at the following publication:
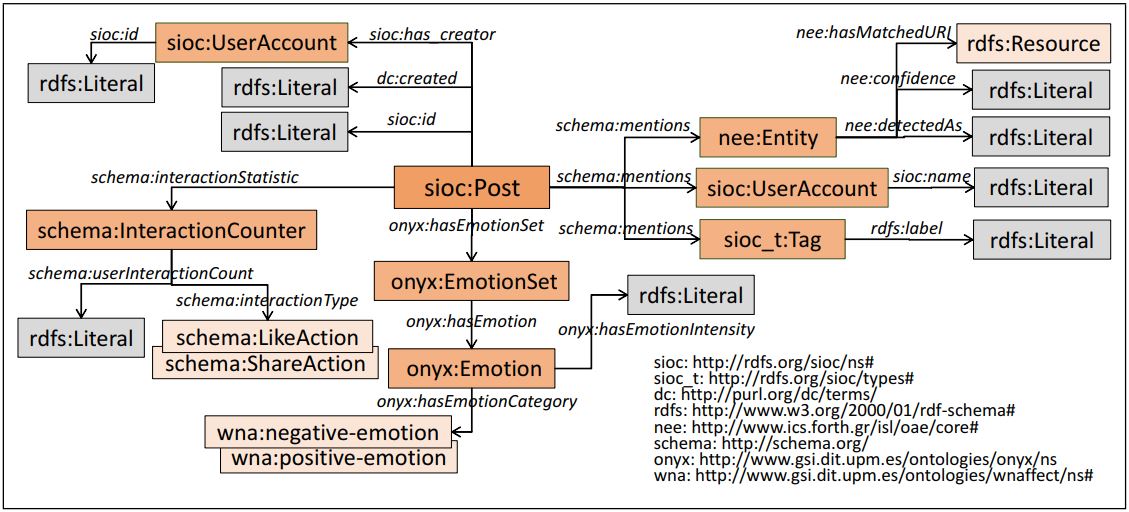
Data Model
The RDF schema used for generating TweetsKB is shown in the following figure:
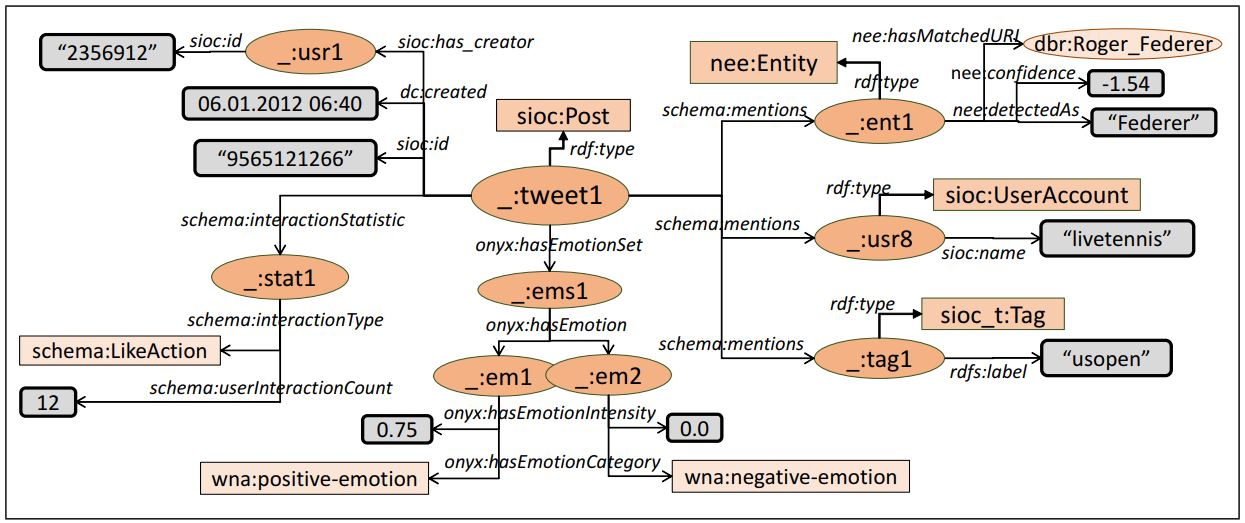
The figure below depicts a set of instances for a single tweet. In this example, the tweet mentions one user account (@livetennis) and one hashtag (#usopen), while the entity name “Federer” was detected, referring probably to the tennis player Roger Federer (with confidence score −1.54/-1.00). Moreover, we see that the tweet has a positive sentiment of 0.75, no negative sentiment, while it has been marked as “favourite” 12 times.
Dataset
TweetsKB is available as Notation3 (N3) files (split by month) through the Zenodo data repository (under a Creative Commons Attribution 4.0 license):